ギョーム中に思い浮かんだので構築してみました。
日本語メインの検索結果をリアルタイムにフィルタリングして表示するビューにおいて、 IME による変換中の振る舞いが気になっていました。
IME で変換中は漢字と仮名と全角英字が混ざるため、単純な実装では漢字へ変換し終えるまで有効な結果になりません。 Google 検索レベルに動くと快適です。
漢字と読み仮名を考慮した絞り込みでは文字列検索パターンが多くなることが予想され、大きなデータセットに対して UI スレッドで行うには速度面での心配があったため、 Web Worker を使って解決を試みました。
サンプルプログラムはこちらから(データの準備が必要です)。
Web Worker
Web Worker とは、メインスレッド(UI) でなくバックグラウンドでもスクリプト処理する仕組みの一つです。重い処理を UI スレッドから逃すことで UI 描画の遅延を防ぐことができます。
Web Worker と UI スレッドとの間は postMessage と event listener を使って互いにやりとりします。
使い所?
Web Worker との通信では JSON オブジェクトなら何でもやり取りできるはずですが、 ArrayBuffer の利用を除けばオブジェクトはコピーされます。
(計測・確認してないが) wasm と同じく通信量が多いと効果が薄そうで、反対に受送信する量が少なく処理が重い場合に、より力を発揮できそうです。
今回の例では、文字列マッチに Web Worker を利用し、初期化時を除いては少数のデータをやり取りするのみにします。
サンプルプログラム
機能としては、18000 項目以上ある日本の観光地の候補をフィルタリングするものが実装されています。
左上の入力欄に文字を入れる度に、観光地名と地名とそれぞれの読み仮名に基づいたフィルタリングを行います。
観光地のデータは 公共クラウドサービス 観光情報ダウンロードサイト の「全件 CSV 」から取得しています。( CC-BY ) Git への commit はしていないため、手元で試す場合は事前のダウンロードとデータ加工( “genData.js” )が必要です。
再掲ですが、サンプルプログラムはこちらから。
構成
このページは読み込み後に観光地データを UI スレッドに読み込んだ上、 Worker に送信します。 Worker が受信すると文字列の正規化処理を行い、それを検索用にストアして初期化を終えます。
ユーザーが入力欄に文字を入れると Worker に入力内容を送信します。 Worker で受信すると入力内容を正規化してマッチした要素の配列インデックスを UI スレッドに返信します。 UI スレッドは受信したインデックスを元に絞り込んだ内容を描画します。
(正規化)
この例での正規化は、漢字入りの名称と仮名の名称をそれぞれ次のように処理します。
- 全角英数字を半角に
- 仮名をローマ字に
この実装では「国会議事堂」が要素にあったときに「国会」と入力してから「国会ぎじどう」としたときに上手くいきません(「東京タワー」の場合は問題ない)。
本題からずれること、特殊な読みのケアが大変なことから修正していません。形態素解析を使いつつ漢字仮名混じりのパターンを列挙すればいけるかもしれません。
動作デモ
データが用意された状態で yarn start すると、アプリケーションが起動します。
動作イメージは下の動画のようになります。「やまとたかだ」 と入力する途中で非同期に表示内容が変わっています。(キャプチャに FPS を喰われているので実際はこの動画よりなめらかに動きます。)
“See all” にチェックすると全項目表示しますが、こちらは DOM 操作が重くなってしまいます。
Worker からはすべてのマッチ項目インデックスが送られていていますがスピードの問題はありません。マッチング処理に本当に時間のかかるアルゴリズムを採用したとしても、 UI スレッド上はこの動作でも以上に遅くならないと思います。
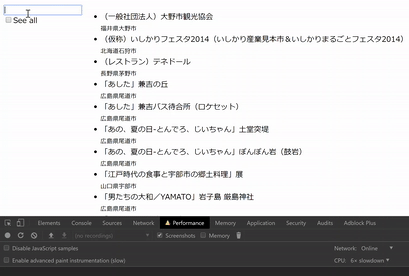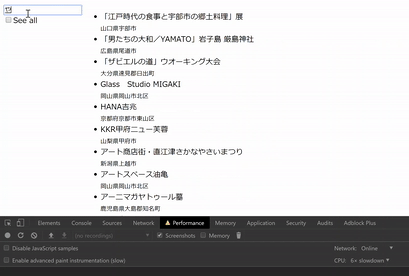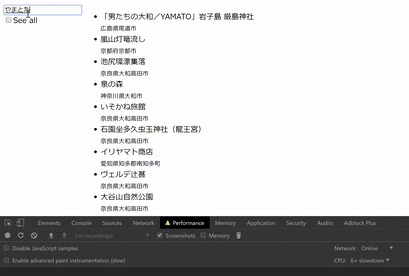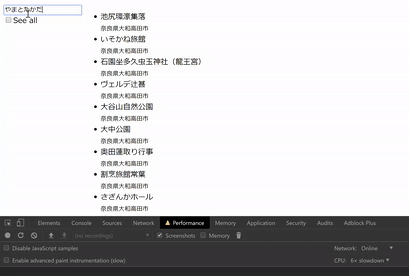 動作イメージ
動作イメージ
まとめ
Web Worker が活用できそうな領域の一つとして、 IME 利用時の快適(?)なフィルタリング機能を UI スレッド外で実装しました。
これを実用化するとすれば、まずは文字列の標準化が問題になりそうです。辞書付きの形態素解析を使ってなんとかするのでしょうか? 日本語と IME を使いながら快適な入力動作・支援をさせるのは難しい。