これは 設計ナイト2020 の感想記事です。
CQRS と GraphQL の話が主な話題でしたが、ディスカッションなどで示唆に富む話を聞けたので、(レポートというよりも)考えたことを書き残しておきます。
発表内容についてはあまり書きませんが、すでに 設計ナイト2020感想 - Qiita と 設計ナイト2020に参加してきました。 | achanBlog という記事があります。 Q&A やディスカッションについても #sekkeinight 付きのツイートを見ると、何が交わされたか把握できると思います。
コンテキスト
DDD・CQRS・GraphQL・アーキテクチャの進化戦略などについて深い話(触ってみたレベルでなく実運用等を経たもの)についても興味深かったのですが、サーバー再度にとっての理想的なモデルとフロントエンドの要求が衝突する境界線について考えるきっかけになりました。もしかしてサーバーとブラウザという境界で分けない方がよいのではないかと。ちょうど業務で API がフロントエンド(というか UI 要求)の実装に引きずられる状況に直面していたのが大きいですが…
「サーバーは王様」
当方はフロントエンドエンジニアですが、「サーバーは王様」という思想には強く同意しています(22:09頃)。(API 利用者という意味の)クライアントからの要求は受け入れるが、その方法はサーバーサイドにとって都合の良い(≠楽な)モデルの元で提供されればよいと思います。
一方、 N+1 問題を考えると効率が悪いため詳細も一度に返すし、様々なデバイスからの要求に答えるため和集合的に情報が加わるなど、現実の API はサーバーサイドのモデルの理想から離れていってしまいがちです。まさに「神 API」です。そうした課題への一つの提案が GraphQL だと理解しています。
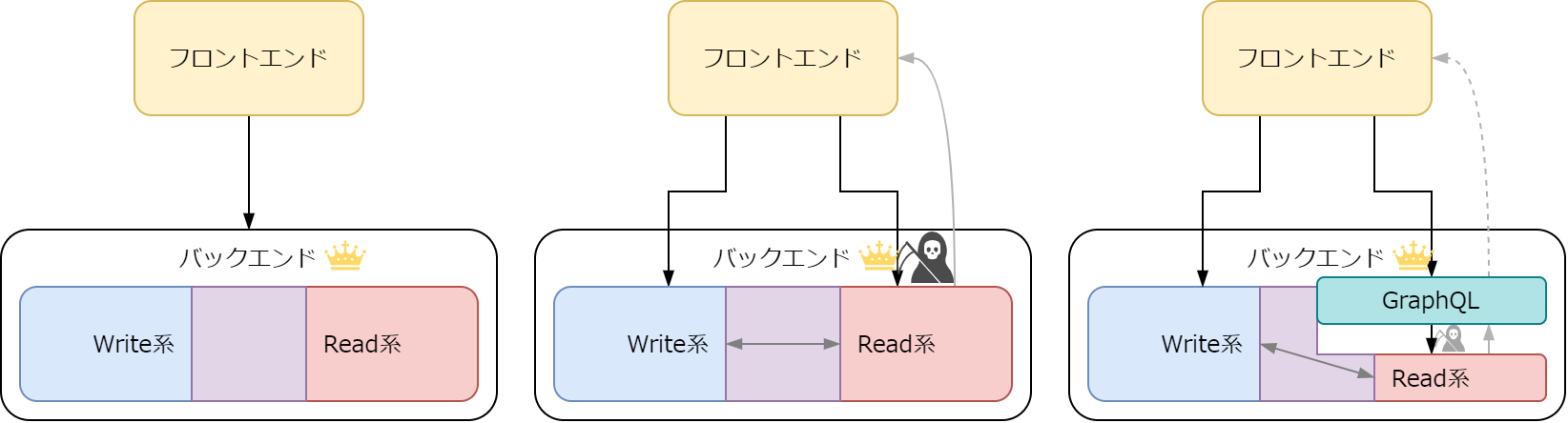 理想と現実と GraphQL
理想と現実と GraphQL(ここの図はあえて死神で。薄い色の線は要求の関心を表す。)
CQRS と担当領域
今回の CQRS の発表資料にあるように、 CQRS で解決できそうな課題の一つは Write 系と Read 系システム要件の違いです。一貫性と可用性、正規化、アクセス特性…。
感覚的に Write 系はクライアントの要求で理想まで歪むことはなさそうですが、 Read 系はドメインモデルでなく(アプリケーションでは)ユーザーのメンタルモデル・情報設計に抗えない影響を受けそうです。 Write 系と Read 系が混在しているともつれがインターフェースにも顔を出して「神 API」を生む可能性を上げるのでしょうか。
また、Read 系で求められるモデルがクライアント要件ベースであるにも関わらず、サーバー上の処理であることから、普通は Read 系もバックエンド担当のエンジニアも実装しています。Write 系でのドメインモデリングに加え、(重要とはいえ)クライアント要求・モデルも詳細まで理解する必要があります。Read 系では関心はクライアントにも向かっており、「サーバーは王様」でいられません。
これは、実際は 2 つの異なるシステムを並列開発しているといえるかもしれません。Read の処理部分を GraphQL サーバーで実装することで、性能への懸念はあれど、 GraphQL は「神 API」を防ぐにとどまらず Read 系のクライアントへの関心を減らしてくれるかもしれません。
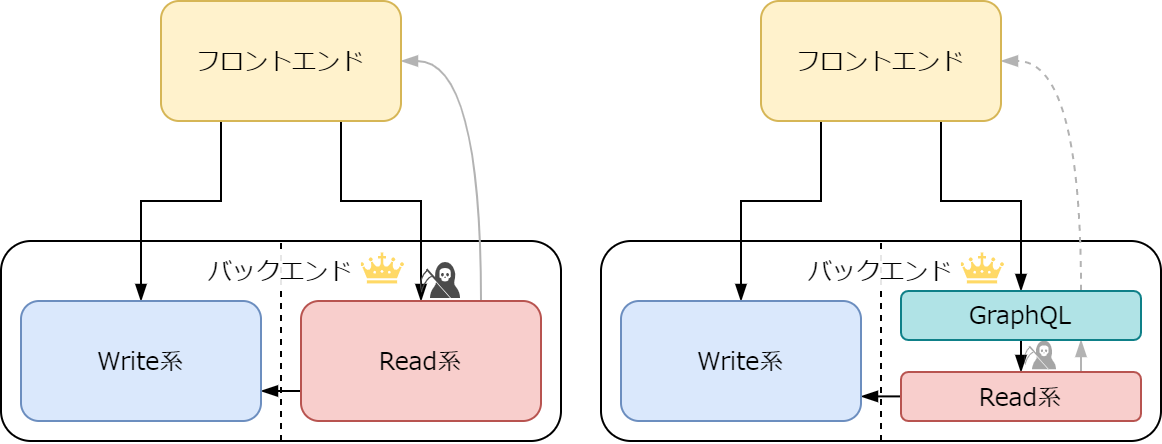 Read 系の関心
Read 系の関心王様の入城
ディスカッションの途中に、クライアントアプリケーションチームの担当領域が Read 系にまで及んでいるチームの話が出てきました(22:18頃)。一瞬、これはやりすぎだろうと感じましたが、後から CQRS の目的を考えたところ考えが変わり、これは理にかなっていると思います。つまり、Write 系は真のデータがある場所・処理という王様で、Read 系は加工された情報がある場所・処理という従者となる形です。サーバーとクライアントアプリケーションがセットの場合、個人的にはサーバー上の Read 系とクライアントアプリケーションを Engagement 系、Write 系を Record 系と捉えています。(SoE/SoR の分類から借用して)
CQRS は見た目 Complex ですが、こうした領域分けをすると関心の歪みが少なく Simple にさえ感じます(さすがに言い過ぎか)。サーバーサイドサブチームとフロントエンドサブチームではなく、ドメインモデリングによりビジネスロジックを明らかにしていく Record 系サブチームとそれをユーザー向けに表現する Engagement 系サブチーム(デザイン含む)という括りで分かれます。 Record 系(≒ Write 系)が今度は王様です。
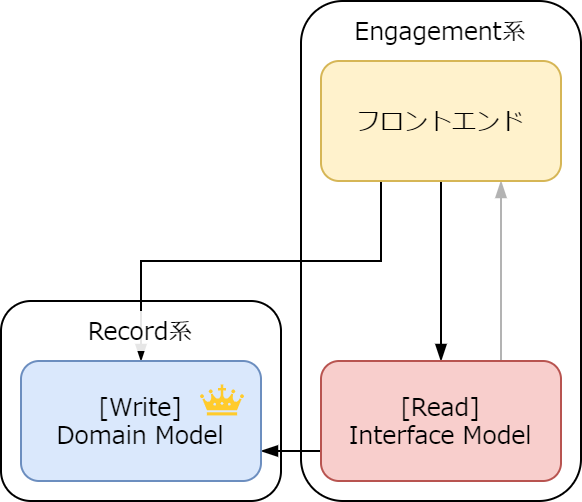 Record 系と Engagement 系
Record 系と Engagement 系この先の良くわからない観点
Record 系 は覆うべきか?
IDDD 本には確かドメインをそのまま API として露出すべきでないと書いてあった気がします。これは Read 系の話の可能性もありますが、 Write 系の話であっても、制約などの知識がクライアント側へ流出する恐れはあります。また、お互い影響しやすいということもあるでしょう(一括追加用の API が Write 系に増えるなど)。Record 系のサブチームが強い気持ちを持つ必要があります。
もしこれが起こりやすい問題だとすると、Record 系を外から使えるままにしてソフト面で抑えるのか、( Engagement 系側で)仲介者を置いて設計で抑えるのか、という選択肢が浮かびます。
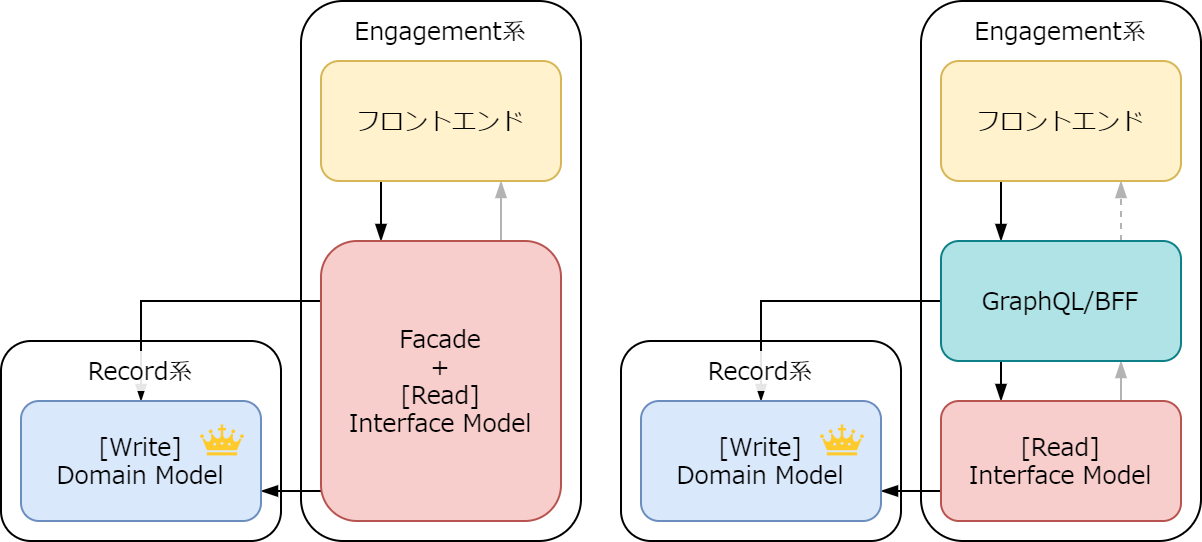 Record 系を覆う場合
Record 系を覆う場合利用者が複数だとどうなる?
この系の分け方は、どちらの系も 1 つしかないからきれいに見えるだけかもしれません。また、Internal な API という条件でのみ役立つのかもしれません。
マルチプラットフォーム
iOS/Android 両対応や Web 版 Mobile 版など、クライアント(フロントエンド)が複数ある場合には、Read 系を共有するパターン、BFF で吸収するパターン、Engagement 系を複数作るパターンが考えられます。
Engagement 系サブチームでRead 系(+BFF)という共有地の担当(サブチーム内チーム)を決める必要があるとか、もしくは、欲しい情報が近いにも関わらず別々に作るため無駄が多い、という問題が起こるかもしれません。
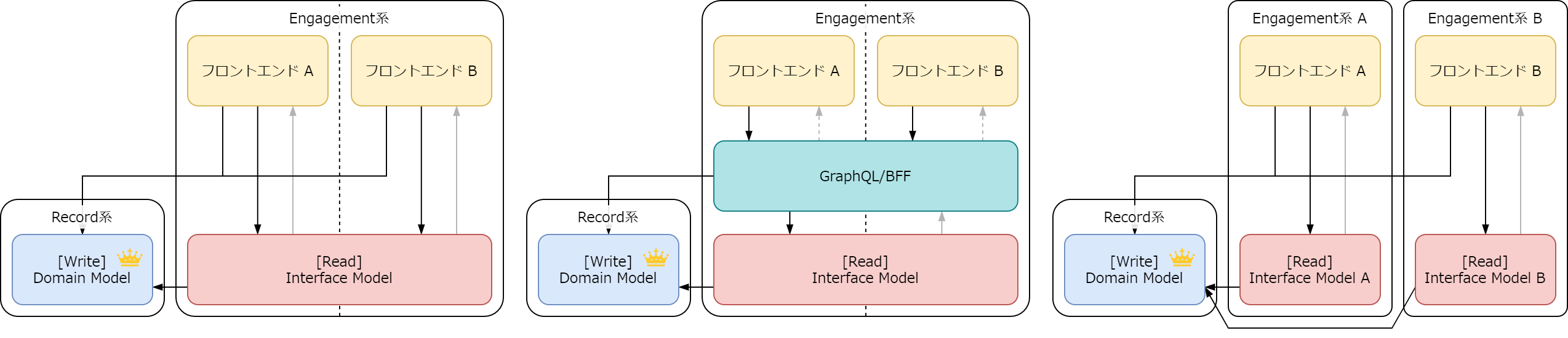 マルチプラットフォームの場合
マルチプラットフォームの場合マイクロサービス・外部連携サービス
マイクロサービスの一部として存在する場合には、誰が利用するかはわからないものの、ドメインとして相応しい要求は受け入れて提供することになります。また、サービス外に極力関心を持たないため、理想的な考えでは特定の利用者は存在しないはずです。
CQRS を採用しているかどうかに関わらず、 Read 系は不明な利用者からの要求には関心を持つはずです(クライアントを取り込むことは NG なので系内で関心を閉じることができない)。一方、利用者が Read 系をそれぞれ作る形は良いとは考えにくく(サービスの詳細に関心を持ちすぎる)、こうなると Record 系と Engagement 系と分けるのは意味がない気がします。
上の仮定を置くと、通常の「モノリス」的アーキテクチャからマイクロサービスアーキテクチャに徐々に移行する場合、もともと Record 系+ Engagement 系と別れたものをまた Write 系と Record 系のペア+クライアントに組みなおす(フロントエンド用には BFF を作りそう)必要があるのは少々問題があると思います(つまりユニバーサルな分け方ではない)。
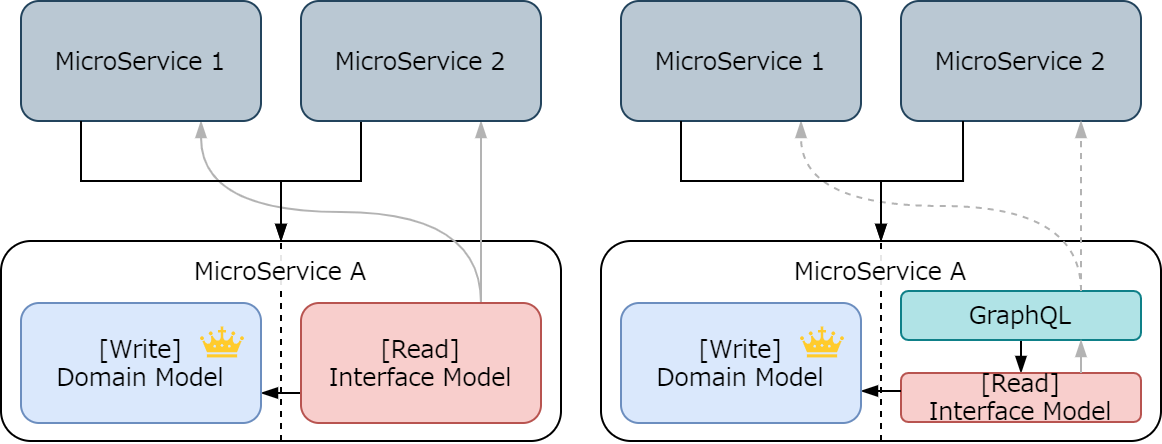 CQRS in マイクロサービス
CQRS in マイクロサービス簡単にできないか?
「CQRS を使う利益> CQRS の大変さ」が成り立てば良い、という議論は、 CQRS は使うべき場面で使おうという意図だったと思います。もし CQRS の実現が簡単になればより CQRS を使える場面は増えることになりますが、これと同時に Read 系の関心の悩みも一緒に解決しやすそうに思えます。
話に挙がった Hasura により Read 系はかなり楽に作れそうです。 Write 系でも Event Sourcing 向きのイベント DB とスナップショット作成の決定版があれば、こちらも楽できそうです。あとは DDD 的にビジネス対象をドメインモデリングすればよいだけ、と理想的にはなります。